
Data Mining/Learning Analytics
The learning and problem-solving tasks in our learning environments (e.g., Betty’s Brain and CTSiM) are complex, open-ended, and choice-rich, so learners must employ a variety of cognitive, metacognitive, and self-regulative skills to achieve success. For example, at the cognitive level in Betty’s Brain, they need to identify and understand relevant information from the resources in the system, represent that information in the causal map format to teach their agent, and use questions and quizzes to explore Betty’s understanding and assess her overall progress. At the metacognitive level, they need to set goals and choose strategies related to their knowledge construction and monitoring tasks. To self-regulate, they have to make choices about how best to use the learning environments they are working in, and how to allocate their time between the different activities. In other words, they must decided when and how to acquire information, build and modify the causal map, check Betty’s progress, and reflect on their own understanding of both the science knowledge and the evolving causal map structure. At the same time, they have to keep track of their progress and regulate & modify their behaviors or seek help when they are unable to make meaningful progress.
Many details of students’ learning activities, as well as additional information like performance on learning and problem-solving tasks, can be tracked by computer-based learning environments (CBLEs). Because the learning activities logged by the system result from a variety of internal cognitive and metacognitive states and processes used by the student, this wealth of data provides opportunities to assess, model, and understand student learning behaviors and strategies more accurately. Further, better understanding and more effective assessment of student learning behaviors can be used to inform and improve learning strategy feedback and support in these systems. However, realizing these opportunities requires effective methods for identifying important learning behavior patterns in the activity trace data.
Our work in educational data mining aims to identify these learning behaviors and strategies through the development of new techniques for modeling and mining student learning activity traces. Our current work includes two primary areas of focus: generation of hidden Markov models to provide an overview of student learning stratgies and sequence mining techniques to identify specific activity patterns corresponding to important student learning behaviors.
Hidden Markov Models
Hidden Markov models (HMMs) can provide an aggregate probabilistic repesentation of students’ internal states and strategies during learning in CBLEs. Analyses that do not take into account the sequential nature of student interactions with the system, such as action frequency counts, capture limited and indirect information about learning strategies and students’ cognitive state. Employing a representation of these internal states and strategies with a probabilistic automaton, such as an HMM, has the potential for facilitating identification, interpretation, and comparison of student learning behaviors. In particular, HMMs can provide a concise, aggregated representation of student learning strategies and behaviors (e.g., strategies and their relationships, as opposed to simple action or action-sequence frequencies) derived from learning activity sequences.
Like a student’s mental processes, the states of an HMM are hidden, meaning that they cannot be directly observed, but they produce observable emissions (in this case, actions in a learning environment). Together, three sets of probabilities form a complete model: (1) transition probabilities, which determine the likelihood of going from one state to another at each step; (2) state output probabilities, which define the likelihood of observing different actions in each state; and (3) state initial probabilities, which define the likelihood that a state will be the starting state for an activity sequence. Our methodology for generating these models from student learning activity traces has facilitated identification, interpretation, and comparison of learning behaviors at an aggregate level.

HMMs generated for two experimental conditions in a recent Betty’s Brain study
Differential Sequence Mining
While hidden Markov models provide an important overview of student learning strategies, their aggregated descriptions of learning behaviors can also mask the exact manifestation of some learning behaviors that are important for a deeper understanding of student behavior and improving feedback and support in the system. To identify and analyze these specific learning behaviors from trace data, we have developed an exploratory data mining methodology, including a differential sequence mining (DSM) technique that provides a finer-grained analysis and more precise definitions of learning behavior differences between groups of students or phases of student activity. The DSM technique uses sequence mining on multiple measures of pattern frquency to identify differentially frequent patterns between two sets of action sequences. In other words, DSM autonomously identifies and ranks patterns that are used more frequently in one group of action sequences than in another. This comparison between groups allows us to identify potentially important patterns. For better identification of important learning behaviors, student activity sequences are also broken up into productive and unproductive phases based on the changes in a performance metric (e.g., how closely the current causal map matches the expert map in a Betty’s Brain unit) using a linear segmentation algorithm. Differential sequence mining is then applied to identify differentially frequent patterns between productive and unproductive phases in a group of students or between corresponding phases in two different groups of students. We interpret identified patterns in terms of student learning behaviors with respect to our cognitive and metacognitive model of student learning in the system. Finally, we investigate the specific instances of promising activity patterns to determine their potential for informing pedagogical feedback and support in the learning environment.

Map score and phase segmentation for example high- and low-performing students in Betty’s Brain
Applying this exploratory data mining methodology to data from Betty’s Brain studies has allowed us to identify a variety of patterns relevant to student learning behaviors that may prove useful for improving feedback from the pedagogical agents. For example, a comparison of high-performing versus low-performing students illustrated that a distinguishing characteristic of the high performers was a tendency to employ reading in a monitoring context (e.g., following a quiz by reading relevant resource pages). Further, other differentially frequent patterns, such as taking a quiz following the addition of a questionable link (e.g., one unrelated to recently read pages in the resources) and then following the quiz with the removal of the questionable link, suggested that students in the high group were also able to effectively use quizzes for monitoring their agent’s (and their own) understanding. In general, the identified patterns from this analysis suggested that high-performing students made more frequent and more effective attempts to monitor their agents’ and their own understanding with both quizzes and reading. In constrast, the low-performing students tended to be most productive when reading resource pages for the first time (as opposed to a variety of re-reading activities observed in the high students’ productive periods) and when they systematically combined reading with editing. However, the low students more often performed extended sequences of only reading or only editing and generally took a less systematic approach to reading and editing in comparison with the high students. Overall, the analysis identified behavioral trends and specific patterns of activity that may be important in triggering and informing strategy feedback for both low-performing and high-performing students.
Action-View representation
When analyzing student’s behavior during their learning and problem-solving activities in an intelligent learning environment, tracking and interpreting individual actions and relations between actions are useful for studying their cognition and learning strategies.
Characterizing actions in too much detail increases the complexity of the modeling task, and may provide diminishing returns. Similarly, studying actions in isolation may not provide enough information to determine strategies students may be employing, i.e., how they are combining their actions to accomplish more complex tasks.
Thus, it is important to appropriately define actions and the corresponding context in which actions are performed, which led us to propose an <action, view> representation. Actions are students’ interactions with the system, while the view capture the corresponding context in which an action was performed.
Students can take the actions (i.e., Take notes, Make an inference, Summarize) based on the information derived from the view (the page content). Since this view is enabled by students navigating to the corresponding page, the view allows us to determine the action-coherent relations (e.g., Page Navigation action → Notes Taking action).
Reinforcement Learning to Enhance Learner Modeling
To develop effective scaffolding schemes that can adapt to specific deficiencies and suboptimal behaviors exhibited by the students, it is important to derive learner models that accurately capture students’ cognitive and metacognitive processes. However, collecting this data from OELE studies, especially in K-12 settings can be difficult and very time-consuming. This may create a data impoverishment problem. To address this issue, we applied a Reinforcement learning (RL) methodology combined with Monte Carlo tree search (MCTS) to systematically increase the amount of the students’ activity data. The enriched data set allows us to learn updated and more complete learner models to represent the students’ learning behaviors.
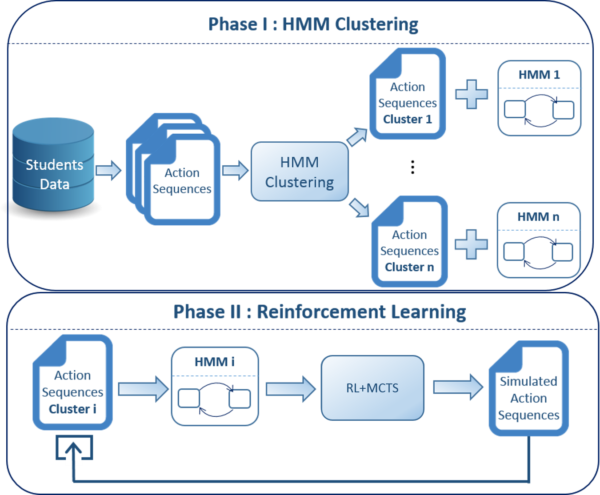
The Figure illustrates the two phases of our learner modeling approach. In the first phase, we apply an Hidden Markov Model (HMM ) clustering method to divide the students into different groups according to similarities in their action sequences, and derive an HMM for each group to represent their learning behaviors. As a next step, we apply the reinforcement learning scheme to generate a number of additional activity sequences that provide more coverage of the students’ learning behaviors for each group. We also extend students’ activity sequences to capture the evolution of their behaviors that can help them become better learners. The Monte Carlo Tree Search (MCTS) algorithm is applied to determine the long-term consequence of an agent interacting with the learning environment, so as to choose the best actions for generating additional or extending students’ activity sequences. These sequences when combined with the original student data are used to generate the updated HMMs that we believe is a more complete description of the students’ learning behaviors and strategies. In the longer term, such models can be employed to provide more relevant scaffolding to the students to help them become better learners.
Our educational data mining tools are implemented in Java and are available by emailing John Kinnebrew [john.s.kinnebrew (AT) vanderbilt.edu] or Gautam Biswas [gautam.biswas (AT) vanderbilt.edu].