![]() This section offers a comprehensive description of the components and operation of the Advanced Computing Center for Research and Education (ACCRE) compute cluster.
This section offers a comprehensive description of the components and operation of the Advanced Computing Center for Research and Education (ACCRE) compute cluster.
A less technical summary suitable for grant proposals and publications is also available.
ACCRE Users By the Numbers
(As of February 2024)
-
2,750
Vanderbilt
Researchers -
9
Vanderbilt Schools and
Colleges Served -
350
Campus Departments and Centers
ACCRE Cluster Details
- 750 Compute Nodes
- 95 Gateway Nodes
- 80 GPU Compute Nodes with approximately 320 GPU cards
- 20,100 Total CPU cores
- 199 TB of Total RAM
- 4.7 PB Storage Space Available through PanFS
- 2.0 PB Storage Space Available through Auristor
- 1.8 PB Storage Space Available through DORS/GPFS
- 27 PB Storage Space Available through LStore
Details of the Cluster Design
The cluster's design incorporates substantial input from investigators using it for research and education. Decisions about the number of nodes, memory per node, and disk space for user data storage are driven by demand. The system's schematic diagram and a glossary of terms used in the cluster's description follow:
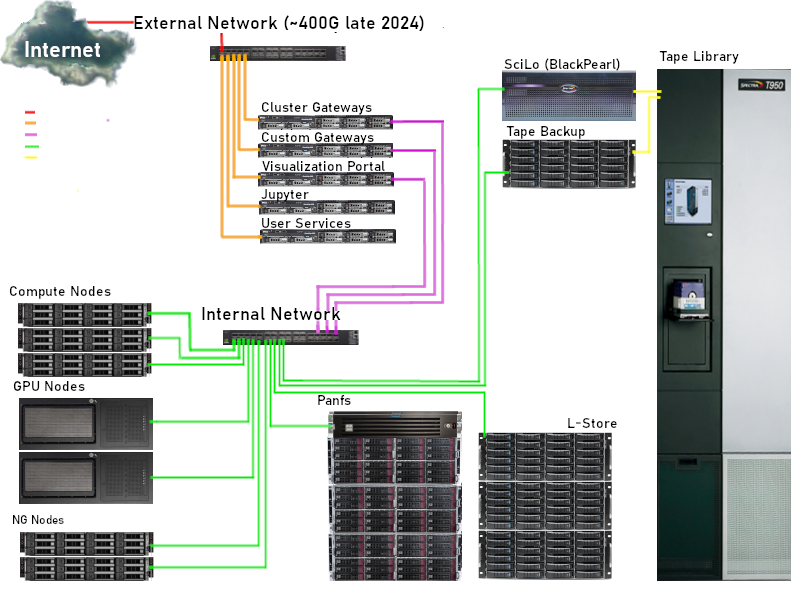
- Bandwidth: The rate of data transfer over the network, typically measured in Megabits/sec (Mbps) or Gigabits/sec (Gbps).
- Compute Node: A node dedicated to running user applications. Direct access to these machines by users is restricted, with access granted only through the job scheduler.
- Disk Server: A machine utilized for data storage. Normal user access to these machines is limited. More information is available in the ACCRE Storage Systems description.
- Gateway or Management Node: Computers designed for interactive login use. Users log in to these machines for tasks such as compiling, editing, debugging programs, and job submission.
- Gigabit Ethernet: Standard networking in servers, offering a bandwidth of 1 Gbps and latency of up to 150 microseconds in Linux environments. In contrast, 10 gigabit ethernet is a high-performance networking solution with a bandwidth of 10 Gbps.
- Latency: The time required to prepare data for transmission over the network.